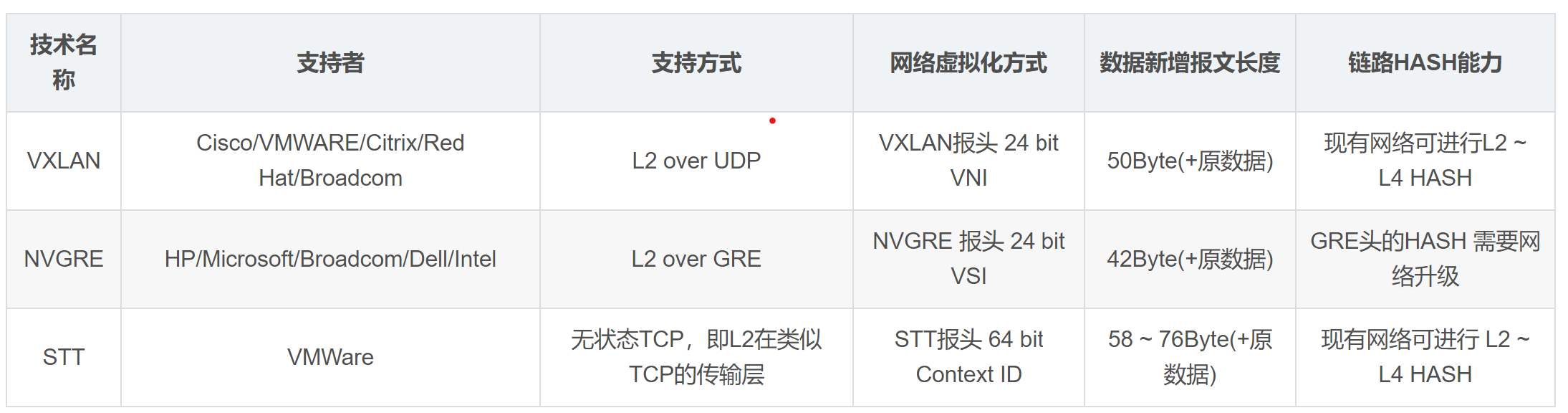
graph TD
A[数据收集] --> B(技术评估)
A --> C(市场评估)
A --> D(团队与生态评估)
A --> E(合规与风险收益)
B --> F[加权总分]
C --> F
D --> F
E --> F
F --> G{决策}
G -->|≥80分| H[重仓配置]
G -->|60-79分| I[观察仓]
G -->|<60分| J[规避]
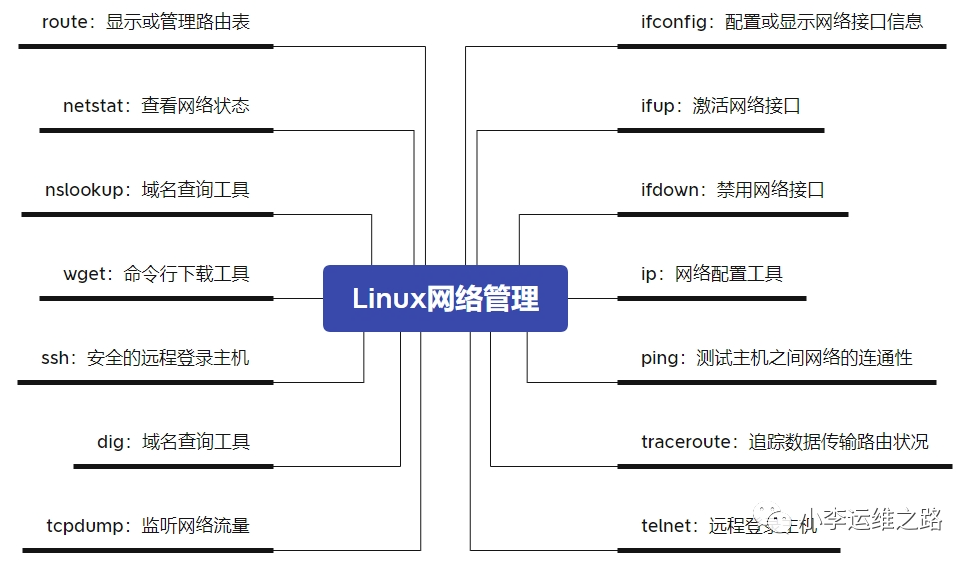
# 查看网卡信息 [root@localhost ~]# ip a # 关闭网卡 [root@localhost ~]# ip link set eth0 down # 开启网卡 [root@localhost ~]# ip link set eth0 up # 添加IP地址 [root@localhost ~]# ip a add 172.16.1.31/24 dev eth0 # 删除IP地址 [root@localhost ~]# ip a del 172.16.1.31/24 dev eth0 # 查看路由 [root@localhost ~]# ip routedefault via 172.16.1.254 dev eth0 proto static metric 100 172.16.1.0/24 dev eth0 proto kernel scope link src 172.16.1.27 metric 100 172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1 172.18.0.0/16 dev br-7f15bb750845 proto kernel scope link src 172.18.0.1
# 端口放通的现象 [root@localhost ~]# telnet 172.16.1.20 22 Trying 172.16.1.20...Connected to 172.16.1.20.Escape character is '^]'.S SH-2.0-OpenSSH_7.4 # 看到这种情况,代表22端口是放通的。 # 端口无法连接的现象 [root@localhost ~]# telnet 172.16.1.20 3306 Trying 172.16.1.20...telnet: connect to address 172.16.1.20: Connection refused
ssh命令——远程登录主机
ssh命令可以使用ssh加密协议实现安全的远程登录服务器,实现对服务器的远程管理。
语法格式:
ssh [选项] [用户]@[主机名或IP地址] [远程执行的命令]
选项:
-p
指定ssh登录端口,默认是22端口
-t
强制分配伪终端
-v
调试模式
操作:
# 首次连接会提示,再次连接就不会提示,输入正确密码就可以远程 [root@k8s-master03 ~]# ssh -p 22 root@172.16.1.20The authenticity of host '172.16.1.20 (172.16.1.20)' can't be established.ECDSA key fingerprint is SHA256:ANt+WLWZpyB8YH14ROYVMTS68fEcEqoIrdVAi2FtwvU.ECDSA key fingerprint is MD5:d0:f1:19:71:df:cb:39:b3:b2:cb:9a:83:39:f2:05:cb.Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added '172.16.1.20' (ECDSA) to the list of known hosts. root@172.16.1.20's password:
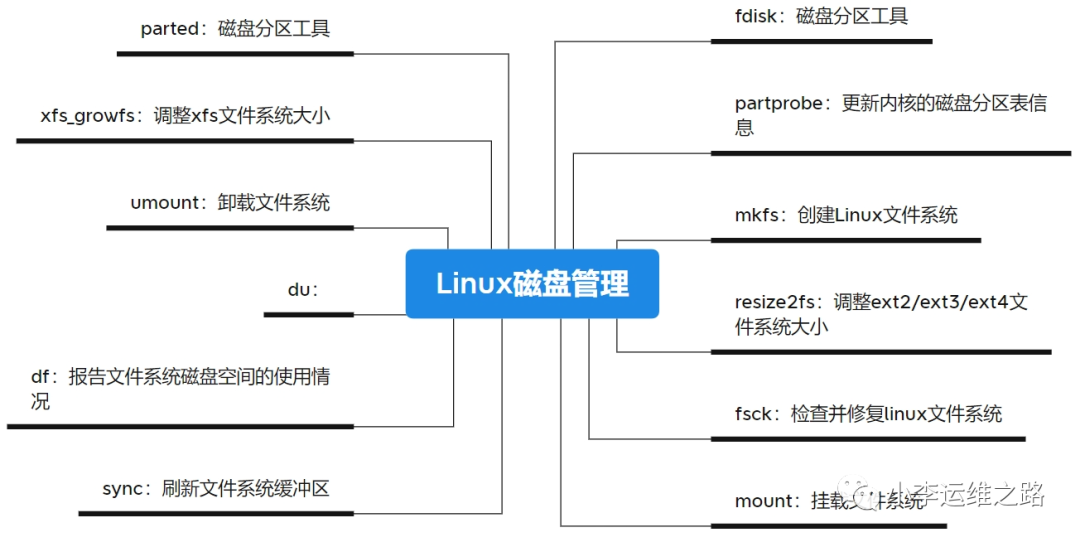
设备 Boot Start End Blocks Id System /dev/vda1 2048 6143 2048 83 Linux /dev/vda2 * 6144 4200447 2097152 83 Linux /dev/vda3 4200448 209715199 102757376 83 Linux
磁盘 /dev/vdc:107.4 GB, 107374182400 字节,209715200 个扇区 Units = 扇区 of 1 * 512 = 512 bytes 扇区大小(逻辑/物理):512 字节 / 512 字节I/O 大小(最小/最佳):512 字节 / 512 字节 [root@localhost ~]# fdisk /dev/vdc 欢迎使用 fdisk (util-linux 2.23.2)。 更改将停留在内存中,直到您决定将更改写入磁盘。使用写入命令前请三思。 Device does not contain a recognized partition table使用磁盘标识符 0x5eb87e6d 创建新的 DOS 磁盘标签。 命令(输入 m 获取帮助):m 命令操作 a toggle a bootable flag b edit bsd disklabel c toggle the dos compatibility flag d delete a partition g create a new empty GPT partition table G create an IRIX (SGI) partition table l list known partition types m print this menu n add a new partition o create a new empty DOS partition table p print the partition table q quit without saving changes s create a new empty Sun disklabel t change a partition's system id u change display/entry units v verify the partition table w write table to disk and exit x extra functionality (experts only)
命令(输入 m 获取帮助): n # 新增加一个分区 Partition type: p primary (0 primary, 0 extended, 4 free) e extendedSelect (default p): p # 新增一个主分区分区号 (1-4,默认 1):1起始 扇区 (2048-209715199,默认为 2048): 将使用默认值 2048 Last 扇区, +扇区 or +size{K,M,G} (2048-209715199,默认为 209715199):+10G分区 1 已设置为 Linux 类型,大小设为 10 GiB
设备 Boot Start End Blocks Id System/dev/vdc1 2048 20973567 10485760 83 Linux
命令(输入 m 获取帮助):t # 更换分区格式已选择分区 1 Hex 代码(输入 L 列出所有代码):L Hex 代码(输入 L 列出所有代码):8e 已将分区“Linux”的类型更改为“Linux LVM” 命令(输入 m 获取帮助):p # 查看 磁盘 /dev/vdc:107.4 GB, 107374182400 字节,209715200 个扇区 Units = 扇区 of 1 * 512 = 512 bytes 扇区大小(逻辑/物理):512 字节 / 512 字节I/O 大小(最小/最佳):512 字节 / 512 字节磁盘标签类型:dos磁盘标识符:0x5eb87e6d
设备 Boot Start End Blocks Id System/dev/vdc1 2048 20973567 10485760 8e Linux LVM 命令(输入 m 获取帮助):w The partition table has been altered! Calling ioctl() to re-read partition table. 正在同步磁盘。 [root@localhost ~]# lsblk # 查看分区情况NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sr0 11:0 1 9.5G 0 rom vda 253:0 0 100G 0 disk ├─vda1 253:1 0 2M 0 part ├─vda2 253:2 0 2G 0 part /boot └─vda3 253:3 0 98G 0 part /vdb 253:16 0 200G 0 disk /datavdc 253:32 0 100G 0 disk └─vdc1 253:33 0 10G 0 part
[root@localhost ~]# parted /dev/vdcGNU Parted 3.1使用 /dev/vdcWelcome to GNU Parted! Type 'help' to view a list of commands.(parted) h align-check TYPE N # 检查磁盘分区 help [COMMAND] # 查看帮助 mklabel,mktable LABEL-TYPE # 创建分区表 mkpart PART-TYPE [FS-TYPE] START END # 创建分区 name NUMBER NAME # 为分区命名 print [devices|free|list,all|NUMBER] # 显示分区表 quit # 退出 resizepart NUMBER END # 重设分区大小 rm NUMBER # 删除编号为NUMBER的分区 select DEVICE # 选择要编辑的分区 set NUMBER FLAG STATE # 改变分区的标志 toggle [NUMBER [FLAG]] # 设置分区标志 unit UNIT # 设置默认单位 version # 显示版本号(parted)
2、创建新分区
# 根据/dev/vdc磁盘创建新分区 [root@localhost ~]# parted /dev/vdc GNU Parted 3.1使用 /dev/vdc(parted) mklabel gpt # 为vdc创建GPT分区表警告: The existing disk label on /dev/vdc will be destroyed and all data on this disk will be lost. Do you want to continue?是/Yes/否/No? yes(parted) mkpart primary 0 5G # 创建主分区,大小为5G警告: The resulting partition is not properly aligned for best performance.忽略/Ignore/放弃/Cancel? Ignore(parted) p # 打印分区表信息Model: Virtio Block Device (virtblk)Disk /dev/vdc: 107GBSector size (logical/physical): 512B/512BPartition Table: gptDisk Flags: Number Start End Size File system Name 标志 1 17.4kB 5000MB 5000MB primary (parted) mkpart logical 5001 10G # 创建逻辑分区,大小为5G(parted) p # 打印分区表信息Model: Virtio Block Device (virtblk)Disk /dev/vdc: 107GBSector size (logical/physical): 512B/512BPartition Table: gptDisk Flags: Number Start End Size File system Name 标志 1 17.4kB 5000MB 5000MB primary 2 5001MB 10.0GB 5000MB logical (parted) q # 退出信息: You may need to update /etc/fstab.
查看分区情况,可见vdc1和vdc2已经创建出来
[root@localhost ~]# lsblkNAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTsr0 11:0 1 9.5G 0 rom /mntvda 253:0 0 100G 0 disk├─vda1 253:1 0 2M 0 part├─vda2 253:2 0 2G 0 part /boot└─vda3 253:3 0 98G 0 part /vdb 253:16 0 200G 0 disk /datavdc 253:32 0 100G 0 disk├─vdc1 253:33 0 4.7G 0 part└─vdc2 253:34 0 4.7G 0 part
3、删除分区
[root@localhost ~]# parted /dev/vdcGNU Parted 3.1使用 /dev/vdcWelcome to GNU Parted! Type 'help' to view a list of commands.(parted) pModel: Virtio Block Device (virtblk)Disk /dev/vdc: 107GBSector size (logical/physical): 512B/512BPartition Table: gptDisk Flags:
Number Start End Size File system Name 标志 1 17.4kB 5000MB 5000MB primary 2 5001MB 10.0GB 5000MB logical
[root@localhost ~]# lsblk # 再次查看分区情况 NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sr0 11:0 1 9.5G 0 rom /mnt vda 253:0 0 100G 0 disk ├─vda1 253:1 0 2M 0 part ├─vda2 253:2 0 2G 0 part /boot └─vda3 253:3 0 98G 0 part /vdb 253:16 0 200G 0 disk /datavdc 253:32 0 100G 0 disk
4、非交互方式创建分区
直接使用一条命令创建一个分区。
[root@localhost ~]# parted /dev/vdc mklabel gpt yes mkpart primary 0 10G Ignore p 警告: The existing disk label on /dev/vdc will be destroyed and all data on this disk will be lost. Do you want to continue? 警告: The resulting partition is not properly aligned for best performance.Model: Virtio Block Device (virtblk)Disk /dev/vdc: 107GBSector size (logical/physical): 512B/512BPartition Table: gptDisk Flags:
Number Start End Size File system Name 标志 1 17.4kB 10.0GB 10000MB primary
# 显示系统的挂载信息 [root@localhost ~]# mount/dev/vda3 on / type xfs (rw,relatime,seclabel,attr2,inode64,noquota)selinuxfs on /sys/fs/selinux type selinuxfs (rw,relatime)nfsd on /proc/fs/nfsd type nfsd (rw,relatime)/dev/vdb on /data type xfs (rw,relatime,seclabel,attr2,inode64,noquota)/dev/vda2 on /boot type xfs (rw,relatime,seclabel,attr2,inode64,noquota)
# 挂载光盘光驱,前提是有光驱镜像 [root@localhost ~]# mount /dev/cdrom /media[root@localhost ~]# ll /media # 挂载nfs文件系统 [root@localhost ~]# mount -t nfs -o nodev,noatime 172.16.1.27:/data /data永久挂载要写入到/etc/fstab中 [root@localhost ~]# cat >> /etc/fstab <<EOF172.16.1.27:/data /data nfs nodev,noatime 0 0EOF # 文件系统只读时,需要重新挂载根目录为读写模式。 [root@localhost ~]# mount -o remount,rw /# 确认fstab文件中配置正确,避免重启失败[root@localhost ~]# mount -a
Linux常用命令之信息显示,掌握关键指令提升效率。详细解析系统信息查看方法,适合初学者与进阶用户。Linux常用命令 信息显示, Linux系统信息显示命令, Linux常用命令大全, Linux文件搜索命令, Linux uname 命令详解, Linux 查看系统信息命令, Linux 命令行信息显示, Linux 系统命令教程, Linux 常用命令之信息查看, Linux 命令行技巧
uname命令——显示系统信息
选项:
-a
显示系统所有相关的信息
-m
显示计算机硬件架构
-n
显示主机名称
-r
显示内核发行版本号
-s
显示内核名称
-v
显示内核版本
-o
显示操作系统名称
常用操作:
[root@localhost ~]# uname -a //显示系统所有相关的信息 Linux localhost.localdomain 3.10.0-1160.el7.x86_64 #1 SMP Mon Oct 19 16:18:59 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux [root@localhost ~]# uname -r //显示内核发行版本 3.10.0-1160.el7.x86_64[root@localhost ~]# uname -v #1 SMP Mon Oct 19 16:18:59 UTC 2020
[root@localhost ~]# dmesg |grep -i error //查看系统启动过程中的错误信息 [ 0.955079] BERT: Boot Error Record Table support is disabled. Enable it by using bert_enable as kernel parameter.
du命令——显示目录或文件所占用的磁盘空间
选项:
-s
显示总计容量
-h
以人为可读的形式显示,以K,M,G为单位
-m
以MB为单位
–exclude=<目录或文件》
忽略指定的目录或文件
常用操作:
[root@localhost ~]# du -sh * //查看当前目录所有子目录和文件的大小 0 anaconda-ks.cfg 4.0K md5.log4.0K test.txt[root@localhost ~]# du -sh md5.log //查看hosts文件大小4.0K md5.log
date命令——显示和设置时间
选项:
-d
显示字符串所指的日期与时间
-s
指定当前系统时间
-u
打印或设置协调世界时(UTC)
时间格式:
%F
显示年月日
%T
显示时分秒
%Y
显示年份
%m
显示月份
%d
显示一个月的第几天
%H
显示时
%M
显示分
%S
显示秒
%w
显示星期几
常用操作
[root@localhost ~]# date //显示当前时间 2023年 10月 22日 星期日 15:29:40 CST [root@localhost ~]# date +%F //显示年月日 2023-10-22
[root@localhost ~]# date +%T //显示时分秒 15:33:35 [root@localhost ~]# date -s "2024-10-22 15:30:00" //设置指定时间 2024年 10月 22日 星期二 15:30:00 CST [root@localhost ~]# date 2024年 10月 22日 星期二 15:30:06 CST
[root@localhost ~]# date +%F -d "100day" //显示100天后的时间 2024-01-30 [root@localhost ~]# date +%F -d "-100day" //显示100天前的时间 2023-07-14 [root@localhost ~]# date +"%Y-%m-%d %H:%M:%S" //指定格式显示当前时间 2023-10-22 15:37:24
坏字符规则:If we mismatch, use knowledge of the mismatched text character to skip alignments 好后缀规则:If we match some characters, use knowledge of the matched characters to skip alignments 2.4 KMP算法 KMP 算法的核心思想,跟上一节讲的 BM 算法非常相近。我们假设主串是 a,模式串是 b。在模式串与主串匹配的过程中,当遇到不可匹配的字符的时候,我们希望找到一些规律,可以将模式串往后多滑动几位,跳过那些肯定不会匹配的情况
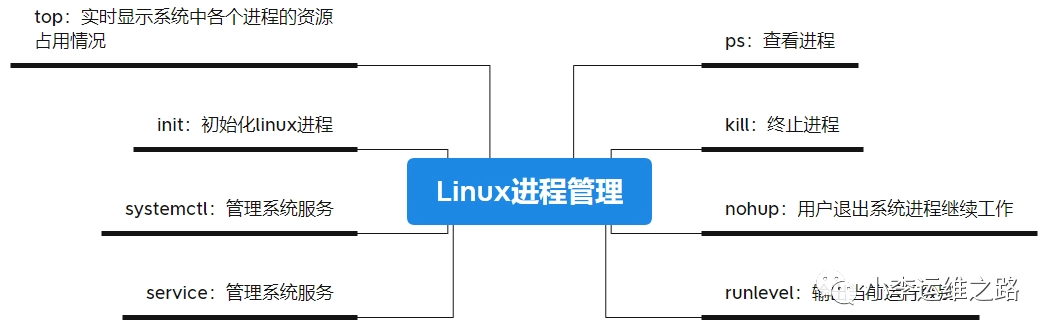
Linux top命令详解:从基础到高阶运维技巧,全面掌握系统监控与性能优化。Linux top命令教程, top命令使用详解, Linux top命令实战指南, Linux top命令基础操作, Linux top命令高级用法, top命令监控系统性能, Linux top命令实时监控, Linux top命令详解, Linux top命令运维实践, top命令参数说明
一、基础操作:实时监控核心界面
1. 启动与界面结构
# 默认3秒刷新(网页1/网页4)
top
# 指定5秒刷新(网页2/网页5)
top -d 5
2. 界面字段详解
区域
关键字段
说明
系统统计
load average
1/5/15分钟平均负载(超核数表示过载)[1,4](@ref)
CPU 状态
%us(用户态)
应用程序直接使用的CPU时间占比[1,4,5](@ref)
内存统计
buff/cache
可回收的缓存内存(网页4/网页5)
二、高阶技巧:精准诊断与优化
1. 进程监控策略
# 监控指定用户进程(网页1/网页5)
top -u john
# 跟踪特定PID及其线程(网页2/网页5)
top -H -p 1234
2. 批处理模式实战
# 生成3次快照用于性能分析(网页2/网页5)
top -b -n 3 > system_profile.log
# 结合awk提取Java进程数据(网页5)
top -b | awk '/java/ {print $1, $6}'
/usr/local/include/pcap/bpf.h:88:1: error: unknown type name ‘u_int’
typedef u_int bpf_u_int32;
^
/usr/local/include/pcap/bpf.h:108:2: error: unknown type name ‘u_int’
u_int bf_len;
^
/usr/local/include/pcap/bpf.h:1260:2: error: unknown type name ‘u_short’
u_short code;
^
/usr/local/include/pcap/bpf.h:1261:2: error: unknown type name ‘u_char’
u_char jt;
^
/usr/local/include/pcap/bpf.h:1262:2: error: unknown type name ‘u_char’
u_char jf;
^
1. ls – 目录内容查看 ls -l # 详细模式(权限/所有者/大小)
ls -a # 显示隐藏文件(包括.和..)
ls -lh # 人性化显示文件大小(KB/MB/GB) 核心选项: – -l:长格式显示详细信息 – -a:显示所有文件(含隐藏文件) – -R:递归列出子目录内容 – -t:按修改时间排序(最新优先)[1,4](@ref)
2. cd – 目录切换 cd ~ # 返回用户家目录
cd .. # 返回上级目录
cd /var/log # 绝对路径切换 特殊用法: – `cd -`:返回上次所在目录 – `cd`:等效于`cd ~`[6,7](@ref)
3. ss – 套接字统计(netstat替代) ss -ta state established # 显示已建立的TCP连接
ss -ltp # 查看监听端口及进程 优势特性: – 显示TCP内部状态(如syn-recv/time-wait) – 支持连接状态过滤 – 性能比netstat快10倍[9,11](@ref)
Disk /dev/sda: 500GB, 500107862016 bytes, 976773168 sectors
这表示系统中存在一个500GB的磁盘设备。
2. 然后使用 smartctl -a /dev/sda 命令。它会显示磁盘的各种详细信息,包括磁盘的型号(其中包含品牌信息)、序列号、固件版本、健康状态等诸多内容。例如,您可能会看到如下输出:
=== START OF INFORMATION SECTION ===
Model Family: Western Digital Blue
Device Model: WDC WD5000LPVX-00V0TT0
Serial Number: 123456789
Firmware Version: 01.01A01